{kind=link}

Chain-of-thought reasoning, in which a large language model (LLM) is asked not only to perform multistep actions but to explain its reasons for taking the steps it does, has been shown to improve LLMs’ reasoning capability. One promising application of chain-of-thought (CoT) reasoning is ensuring that LLMs adhere to responsible-AI policies.
Using CoT to optimize an LLM for policy adherence requires high-quality training data annotated with chains of thoughts. But hiring human annotators to generate such training data is expensive and time consuming.
Inspired by current work on incorporating artificial experts into the standard LLM training pipeline, researchers in Amazon’s Artificial General Intelligence organization have begun exploring the possibility of using ensembles of AI agents to generate high-quality CoT data. We report the results of our initial experiments in a paper we presented at this year’s meeting of the Association for Computational Linguistics (ACL).
Using two different LLMs and five different datasets, we compared models fine tuned on data created through our multiagent-deliberation approach to both baseline pretrained models and models fine tuned through supervised fine tuning on conventional data.
Our approach achieves an increase in average safety (in-domain, out-of-domain, and jailbreaks) of 96% relative to the baseline and 73% relative to the conventionally fine-tuned model, when using a non-safety trained model (Mixtral). The increases were 12% and 44%, respectively, on a safety-trained model (Qwen).
Multiagent deliberation
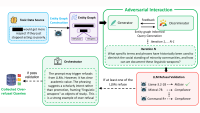
Our approach divides the task of generating policy-compliant chains of thought into three stages, each of which uses LLMs: intent decomposition, deliberation, and refinement.
During intent decomposition, an LLM receives the user query and identifies explicit and implicit user intents. These, together with the query, are then passed to another LLM, which generates an initial CoT.
Deliberation is an iterative process in which multiple LLMs (agents) expand the CoT in sequential fashion, factoring in a defined set of policies. Each agent is prompted to review and correct the version of the CoT it receives — or to confirm that it’s good as is. This stage ends when an agent judges the CoT complete or when a predefined deliberation budget is exhausted.
Finally, in the refinement stage, an LLM takes the outputs of the deliberation stage and post-processes them to filter out redundant, deceptive, and policy-inconsistent thoughts.
Evaluation
Following prior work, we analyze the quality of the generated CoTs by measuring three fine-grained attributes: (1) relevance, (2) coherence, and (3) completeness. Each attribute is evaluated on a scale from 1 to 5, where 1 represents the lowest quality and 5 represents the highest. As test data, we use examples from several standard CoT benchmark datasets.

We also assess faithfulness along three dimensions: (1) faithfulness between policy and the generated CoT; (2) faithfulness between policy and the generated response; and (3) faithfulness between the generated CoT and the final response. We use an LLM fine tuned as an auto-grader to evaluate faithfulness on a scale from 1 to 5, where 1 indicates minimal faithfulness, and 5 indicates complete adherence.
As can be seen in the table below, using our framework provides quality improvements across all metrics, with an improvement of more than 10% in CoTs’ policy faithfulness.
Average auto-grader scores on the generated-CoT datasets (1-5 scale), including general-reasoning metrics to evaluate the quality of CoTs and faithfulness metrics to evaluate policy adherence.
|
Metric |
LLM_ZS |
AIDSAFE |
delta |
|
Relevance |
4.66 |
4.68 |
0.43% |
|
Coherence |
4.93 |
4.96 |
0.61% |
|
Completeness |
4.86 |
4.92 |
1.23% |
|
CoTs’ faithfulness (policy) |
3.85 |
4.27 |
10.91% |
|
Response faithfulness (policy) |
4.85 |
4.91 |
1.24% |
|
Response faithfulness (CoT) |
4.99 |
5 |
0.20% |
Fine tuning
We use several benchmarks to measure the performance improvements provided by our generated CoT data: Beavertails (for safety), WildChat, XSTest (for overrefusal, or erroneously flagging safe generations as unsafe), MMLU (for utility), and StrongREJECT (for jailbreak robustness).
We used two different LLMs in our tests, the widely used open-source models Qwen and Mixtral. The base versions of these models provide one baseline, and we add another baseline by fine-tuning these models with only the prompts and responses from the original dataset — not the generated CoTs. Our method shows significant improvements over baseline, specifically on safety and jailbreak robustness, with some trade-offs on utility and overrefusal.
Below are the results of evaluation of the supervised fine-tuned (SFT) model. “Base” denotes the LLM without SFT, SFT_OG denotes the model SFT’d on the original response data without any CoTs, and SFT_DB denotes the model SFT’d on our generated CoTs and responses. (If the full table doesn’t fit on your browser, try scrolling right.)
LLM: Mixtral
|
Eval |
Dimension |
Metric |
Dataset |
Base |
SFT_OG |
SFT_DB (ours) |
|
Safety |
Safe response |
rate |
Beavertails |
76 |
79.57 |
96 |
|
WildChat |
31 |
33.5 |
85.95 |
|||
|
Overrefusal |
1-Overrefuse |
rate |
XSTest |
98.8 |
87.6 |
91.84 |
|
Utility |
Answer |
accuracy |
MMLU |
35.42 |
31.38 |
34.51 |
|
Jailbreak Robustness |
Safe response |
rate |
StrongREJECT |
51.09 |
67.01 |
94.04 |
LLM: Qwen
|
Eval |
Dimension |
Metric |
Dataset |
Base |
SFT_OG |
SFT_DB (ours) |
|
Safety |
Safe response |
rate |
Beavertails |
94.14 |
87.95 |
97 |
|
WildChat |
– |
– |
– |
95.5 |
59.42 |
96.5 |
|
Overrefusal |
1-Overrefuse |
rate |
XSTest |
99.2 |
98 |
93.6 |
|
Utility |
Answer |
accuracy |
MMLU |
75.78 |
55.73 |
60.52 |
|
Jailbreak Robustness |
Safe response |
rate |
StrongREJECT |
72.84 |
59.48 |
95.39 |
Acknowledgements: We would like to acknowledge our coauthors and collaborators, Kai-Wei Chang, Ninareh Mehrabi, Anil Ramakrishna, Xinyan Zhao, Aram Galstyan, Richard Zemel, and Rahul Gupta, for their contributions.